Mirar (tu smartphone) para cuidar
Leo sobre el programa Mirar para cuidar, la campaña de acción voluntaria para controlar el cumplimiento del acuerdo de precios con los supermercados.
Leo sobre el programa Mirar para cuidar, la campaña de acción voluntaria para controlar el cumplimiento del acuerdo de precios con los supermercados.
pip es una herramienta esencial para el trabajo diario de un programador python: es el manejador de paquetes de nuestro entorno de trabajo (¡virtual por favor!), con el que instalamos, actualizamos o eliminamos las dependencias de nuestro proyecto (y, recursivamente, las dependencias que estas pudieran tener).
Soy vago. Por eso me llevo bien con Git, que permite reconocer un changeset con un pedacito de su hash sha1 :
Git is smart enough to figure out what commit you meant to type if you provide the first few characters, as long as your partial SHA-1 is at least four characters long and unambiguous — that is, only one object in the current repository begins with that partial SHA-1.
Estimando cuanto trabajo significa actualizar Cuevana sources y/o Cuevanalib investigué cómo funciona la nueva versión de cuevana.
Estas notas son el resultado de lo que fui observando.
Una vez que se elige un contenido, un iframe apunta a una URL con este forma:
En código javascript inline define las fuentes disponibles para ese contenido
var plugin_ver = 5, plugin_rev = 0; var actual_ver, actual_rev; var sources = { "2": { "360": ["uptobox", "uploadcore", "vidbull", "bayfiles", "filebox", "cramit", "zalaa"], "720": ["uploadcore", "vidbull", "bayfiles", "cramit"] } }, sel_source = 0;
La primer clave (en este caso 2, inglés) es el idioma del audio,
y la segunda la calidad del video
Luego define diferentes constates:
var label = { '360': 'SD (360p)', '480': 'SD (480p)', '720': 'HD (720p)', '1080': 'HD (1080p)' }; var labeli = { "1": "Espa\u00f1ol", "2": "Ingl\u00e9s", "3": "Portugu\u00e9s", "4": "Alem\u00e1n", "5": "Franc\u00e9s", "6": "Coreano", "7": "Italiano", "8": "Tailand\u00e9s", "9": "Ruso", "10": "Mongol", "11": "Polaco", "12": "Esloveno", "13": "Sueco", "14": "Griego", "15": "Canton\u00e9s", "16": "Japon\u00e9s", "17": "Dan\u00e9s", "18": "Neerland\u00e9s", "19": "Hebreo", "20": "Serbio", "21": "\u00c1rabe", "22": "Hindi", "23": "Noruego", "24": "Turco", "26": "Mandar\u00edn", "27": "Nepal\u00e9s", "28": "Rumano", "29": "Iran\u00ed", "30": "Est\u00f3n", "31": "Bosnio", "32": "Checo", "33": "Croata", "34": "Fin\u00e9s", "35": "H\u00fanagro", "36": "Persa", "38": "Indonesio" }; var labelh = { 'filebox': 'Filebox', 'uptobox': 'Uptobox (NUEVO)', 'uploadcore': 'Uploadcore (NUEVO)', 'vidbull': 'Vidbull (NUEVO)', 'zalaa': 'Zalaa', 'cramit': 'Cramit', '180upload': '180upload', 'bayfiles': 'Bayfiles' };
El usuario selecciona mediante un menú donde se define audio, quality y source
que se configuran como atributos data del link:
.. code-block::
<a class="sel" data-type="quality" data-id="360">SD (360p)</a>
Donde data-type es el tipo de variable, data-id el valor para esa opción
y class="sel" determina si esa es la opción seleccionada.
Cuando se hace click en el botón Play se invoca la URL:
http://www.cuevana.tv/player/source_get?def=**quality**&audio=**audio**&host=**source**&id=4773&tipo=pelicula
Por ejemplo:
http://www.cuevana.tv/player/source_get?def=360&audio=2&host=bayfiles&id=4773&tipo=pelicula
Esta página presenta el captcha, que una vez superado redirige a la URL:
http://go.cuevana.tv/?*URL_DESTINO*
Por ejemplo:
http://go.cuevana.tv/?http%3A%2F%2Fbayfiles.com%2Ffile%2FvIsf%2FkTvfNj%2Fthe.apparition.2012.bdrip.xvid-sparks.mp4%3Fcid%3D4773%26ctipo%3Dpelicula%26cdef%3D360
Que a su vez redirige a URL_DESTINO que es la URL del servicio donde el video está hosteado
con parámetros extra: ?cid=4773&ctipo=pelicula&cdef=360. En el ejemplo anterior:
Aquí entra en juego el "plugin de cuevana". Se puede bajar por ejemplo
la versión para Firefox desde http://www.cuevana.tv/player/plugins/cstream-5.0.xpi
Descomprimirlo con unzip y abrir el archivo content/cuevanastream.js
La presencia de los parámetros cid``y ``ctipo y una url de alguno de los servicios
que usa Cuevana hace que se inyecte un javascript en la URL del servicio.
var loc = (window.location.href.match(/cid=/i) && window.location.href.match(/ctipo=/i)); if (window.location.href.match(/^http:\/\/(www\.)?bayfiles\.com/i) && loc) { addScript('bayfiles'); } // más servicios else if (window.location.href.match(/^http:\/\/(www\.|beta\.)?cuevana\.(com|co|tv|me)/i)) { var n = document.createElement('div'); n.id = 'plugin_ok'; n.setAttribute('data-version', '5'); n.setAttribute('data-revision', '0'); document.body.appendChild(n); } function addScript(id) { var s = document.createElement('script'); s.setAttribute('type', 'text/javascript'); s.setAttribute('src', 'http://sc.cuevana.tv/player/scripts/5/' + id + '.js'); document.getElementsByTagName('head')[0].appendChild(s); }
En ese caso se inyecta el javascript:
http://sc.cuevana.tv/player/scripts/5/bayfiles.js
Que es el encargado de parsear html para obtener la url real de descarga, resolver/exponer el captcha si existiera, esperar el tiempo de guarda del servicio y redirigir al reproductor de cuevana:
window.location.href = 'http://www.cuevana.tv/#!/' + tipo + '/' + id + '/play/url:' + encodeURIComponent(a) + '/def:' + vars['cdef'];
Donde tipo es series o peliculas, id es el identificador del contenido,
def es 360 o 720 y a es la url final del archivo mp4
http://www.cuevana.tv/#!/' + tipo + '/' + id + '/play/url:' + encodeURIComponent(a) + '/def:' + vars['cdef'];
El reproductor carga el subtitulo desde la siguientes URL.
Para series:
http://sc.cuevana.tv/files/s/sub/ID**_**LANG.srt
Donde ID es el identificador del contenido y LANG es el código
del idioma en 2 letras mayúsculas (ES, EN, etc.)
Para contenidos HD se agrega el sufijo _720:
http://sc.cuevana.tv/files/s/sub/**ID**_**LANG**_720.srt
Para peliculas es análogo pero un nivel más arriba:
http://sc.cuevana.tv/files/sub/**ID**_**LANG**.srt
Y eso es todo lo que necesitamos saber.
nose es un excelente framework para testing en python. Es mucho más
que un testrunner inteligente: tiene un conjunto de extensiones y shortcuts
de aserciones de unittest, soporta fixtures y setups/teardown
por paquetes, y viene con un montón de plugins incorporados.
"nose extends unittest to make testing easier"
dice el eslogan y eso es lo que queremos: tests más fáciles de escribir, más rápidos de ejecutar.
De plugins y opciones que potencian esta idea se trata este post.
Ah, beautiful dots
"Puntito, puntito, puntito, puntito...", cuenta mi mente en standby cuando los test van pasando, como ovejitas que saltan un cerco. Pero, oh desdicha, una "efe", la oveja negra que falla, aparece en la pantalla y la ansiedad por saber cuál nos invade.
El problema es que por default (con --verbose=1), nose
pospone el detalle de errores y fallos hasta el final de la corrida.
En suites gigantes (que demoran más de 30 minutos en completarse,
por ejemplo) esto es un engorro.
nose-progressive reemplaza la interfaz de usuario por una mucho más amigable y bonita. En vez de puntitos, una barra de progreso al pie de la pantalla va indicando el progreso satisfactorio, y deja el resto de la pantalla para mostrar errores y fallos on the fly.
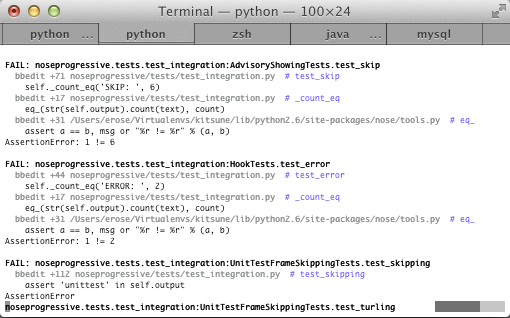
Como si fuera poco, te da shortcuts a la línea donde se produjo un fallo
(por ejemplo: vim +258 common/tests/test_guideplan.py), simplifica los
tracebacks a la parte útil, e incluye colores usados con criterio
(basada en la genial biblioteca blessing, del mismo autor).
Para instalarlo, lo de siempre:
Para usarlo, agregar --with-progressive como parámetros de nosetests,
o bien, para usarlo siempre, configurarlo en .noserc o en la
variable NOSE_ARGS de django-nose
Si trabajás con Django esto quizas suene a perogrullada, pero django-nose es la vuelta de tuerca que faltaba para que la nariz brille en este entorno. Con django-nose por defecto sólo se corren los tests del proyecto y no los de todas las aplicaciones instaladas (que, se supone, tienen sus propios tests).
Y entre otras opciones o, tiene un modo de reuso de la base de datos,
(configurando REUSE_DB=1 como variable de entorno), que nos evita la creación
de tablas en cada corrida, ahorrando unos cuantos segundos de setup en aplicaciones
como muchos modelos. Por supuesto, si la base de datos cambia (porque
se agregó un modelo o se se migró con South) tenés que asegurarte
que la variable está en 0 para que cree la última version
La opción --with-id
(estrictamente el plugin TestId, que viene en las baterías incluídas de nose)
le asigna un número único a cada test ejecutado,
y los guarda en el archivito .noseids junto con su path y el
resultado de la última corrida.
Lo bueno es que pasando --with-id --failed nose usa esa información
y ejecuta solamente los tests que fallaron en la última corrida,
permitiendo una rápida iteración "falla/corrección".
Frecuentemente sucede que tenemos caso (una subclase de TestCase)
con muchas pruebas (métodos) que están lógicamente agrupadas
porque comparten un setup, por ejemplo,
y sin embargo sólo queremos correr un subconjunto.
Sabemos que como es inteligente y poco burocrático, nose no sólo ejecuta
tests definidos como subclases de unittest.TestCase sino
cualquier paquete, módulo, función o clase
que matchee una expresión regular, que por defecto es (?:^|[b_./-])[Tt]est
Con el parámetro -m
se puede redefinir este patrón, pero igualmente no aplica a nivel
métodos.
Por eso existe nose-selecttests, que permite filtrar pruebas con determinada subcadena en el nombre del método.
Por ejemplo:
$ djntest -v 2 common/tests/test_sequence_diff.py #2976 test_differ_in_fk (cpi_mrp.apps.common.tests.test_sequence_diff.TestInstanceDiff) ... ok #2977 test_differ_in_m2m (cpi_mrp.apps.common.tests.test_sequence_diff.TestInstanceDiff) ... ok #2979 test_multiple_diff (cpi_mrp.apps.common.tests.test_sequence_diff.TestInstanceDiff) ... ok #2980 test_only_compare_same_type (cpi_mrp.apps.common.tests.test_sequence_diff.TestInstanceDiff) ... ok ---------------------------------------------------------------------- Ran 4 tests in 0.375s
En cambio:
$ djntest --select-tests=differ -v 2 apps/common/tests/test_sequence_diff.py #2976 test_differ_in_fk (cpi_mrp.apps.common.tests.test_sequence_diff.TestInstanceDiff) ... ok #2977 test_differ_in_m2m (cpi_mrp.apps.common.tests.test_sequence_diff.TestInstanceDiff) ... ok ---------------------------------------------------------------------- Ran 2 tests in 0.088s
Esta herramienta no es estrictamente un plugin de nose, sino un helper que aprovecha las posibilidades de bash para autocompletar usando la tecla tab.
¿Para qué sirve? nose acepta un path (o muchos) para especificar qué test correr:
Pero también permite afinar la puntería y "meterse" adentro del módulo:
E incluso adentro del testcase:
Desde el : en adelante estamos en Python y Bash ya no sabe autocompletar,
salvo que usemos esta herramienta que instrospecciona y "alimenta" el
autocompleter.
Lo hizo Javi Mansilla en Machinalis y busca ayuda para mejorarlo y generalizarlo.
¿No sería buenísimo que esto estuviese built-in en nose? ¿Nos ayudarías?
¿Cuánto tiempo insume cada test? Instalá nose-timer y activalo (con --with-timer)
para saber la respuesta.
nose tiene una opción --pdb (o la más estricta --ipdb-failures)
que nos manda al debugger cuando un test falla o da error.
nose-ipdb lo imita, pero usando el más pulenta de los debuggers: ipdb.
Suficiente por hoy. Pero ¿me estoy perdiendo alguna cosa interesante para meter en mi nariz?