Mi plantilla personalizada para proyectos Python
Python, como el lenguaje pragmático que es, no exige mucho para empezar. Un archivo de texto con código válido, que por convención lleva la extensión .py y constituye un "módulo" en la jerga pythónica, ya es un pequeño programa (un script); lo ejecutamos con python <archivo> y a cobrar. Pero cuando esa simple pieza de código necesita crecer a más archivos o merece ser distribuida, quizás porque será dependencia de otro proyecto o simplemente porque consideramos que a alguien le servirá, entonces necesita algo de estructura y metadatos.
Esto no es algo exclusivo de Python: cuando se comienza un proyecto de software siempre hay una serie de archivos y estructuras básicas que sirven como punto de partida; el conjunto mínimo de archivos y carpetas, configuraciones y código "básico" que se necesita cuando se desea compartir el código como una aplicación o biblioteca: el boilerplate de un proyecto. El boilerplate no define lógica, pero sí establece la base técnica, muchas veces basada en convenciones y otras en gustos personales, sobre la cual se construirá todo lo demás.
Este artículo detalla las decisiones que hice para la plantilla e inicialización automatizada (el "bootstrapping") que uso para mis proyectos, basada en la herramienta Copier.
Si querés probar, la plantilla está en mgaitan/python-package-copier-template y podés crear un proyecto nuevo a partir de ella así:
uvx --with=copier-template-extensions copier copy --trust "gh:mgaitan/python-package-copier-template" /path/to/your/new/project
Lo destacado:
- 🐍 Paquete Python moderno (+3.12) con configuración centralizada en
pyproject.toml. - 📦 Build y gestión de dependencias con uv, distinguidas por grupos (dev/qa/docs).
- 🧹 Linter y formateado vía Ruff con un conjunto amplio de reglas habilitadas.
- ✅ Type checking vía ty.
- 🧪 Tests con pytest, coverage.py y otras extensiones
- 📚 Documentación con Sphinx, MyST y algunas extensiones, desplegada en GitHub Pages
- 🤖 Automatización de la creación de proyecto en GitHub vía GitHub CLI
- ⚙️ Workflow de CI en GitHub Actions
- 🚀 Workflow para releases automáticos vía Trusted Publishing
- 🧠 Defaults vía introspección para minimizar las decisiones durante el cuestionario inicial
- 🛠️ Makefile con algunos atajos para tareas comunes
- 📄 Generación de documentos genéricos como LICENSE/CODE_OF_CONDUCTS/AGENTS.md, etc.
- 🌀 Setup inicial del entorno de desarrollo y repositorio git
- ♻️ Proyectos actualizables con
copier update
Y muchos más detalles que me estoy olvidando ahora.
Un bootstrapping mínimo en Python
Empezemos por dar algo de contexto. Un boilerplate mínimo para un proyecto Python actual, instalable y distribuible se puede crear con [uv init](https://docs.astral.sh/uv/concepts/projects/init/#packaged-applications) (que está fuertemente inspirado en cargo init para Rust):
$ uv init demo-project --package Initialized project `demo-project` at `/home/tin/lab/demo-project`
Lo que resulta en esto
$ tree demo-project/ demo-project/ ├── pyproject.toml ├── README.md └── src └── demo_project └── __init__.py 3 directories, 3 files $ cat demo-project/pyproject.toml [project] name = "demo-project" version = "0.1.0" description = "Add your description here" readme = "README.md" authors = [ { name = "Martín Gaitán", email = "gaitan@gmail.com" } ] requires-python = ">=3.14" dependencies = [] [project.scripts] demo-project = "demo_project:main" [build-system] requires = ["uv_build>=0.9.9,<0.10.0"] build-backend = "uv_build"
Este boilerplate declara demo-project como CLI, asociado a la función main que es un placeholder para reemplazar con tu código.
$ cd demo-project/ $ cat src/demo_project/__init__.py def main() -> None: print("Hello from demo-project!") $ uv run demo-project Using CPython 3.14.0 Creating virtual environment at: .venv Installed 1 package in 6ms Hello from demo-project!
Si instalaras tu programa con uv tool install . desde el directorio del proyecto podrás ejecutar demo-project desde cualquier lado.
Un boilerplate a medida
Como dije, eso es lo mínimo. Cualquier proyecto que se precie define tests unitarios (y cómo ejecutarlos), declara dependencias auxiliares para desarrollo, configura uno o más linter con reglas de estilo, idealmente tiene documentación, incluye algún workflow de integración continua, se versiona con git, y hasta se le ponen "badges" en la cabecera del README. ¿Qué framework de tests usamos? ¿Con qué generamos la documentación? ¿El proyecto estará en un layout src/ o flat?
Son un montón de decisiones a tomar (que eventualmente pueden cambiar) y un montón de trabajo implementarlas a mano. Más aún, cuando nos acostumbramos a una manera, muchas veces queremos lo mismo en todos los proyectos.
Acá es cuando entra el concepto de scaffolding, que es generar el boilerplate a partir de plantillas editables de manera centralizada. Quizás la manera más genérica y trivial de hacer estas plantillas para proyectos sea la de marcar un repositorio en GitHub como "template" de modo que cuando uno inicia un proyecto, en vez de empezar con el repositorio vacío se inicia desde el estado HEAD del repositorio template (pero sin ser un fork de este).
Pero iniciar un proyecto no es solo crear el boilerplate, sino también preparar el entorno de desarrollo, inicializar el repo, crear el proyecto en GitHub y quizás pushear un primer commit, revisar que el nombre que elegimos para el paquete no está ya registrado, etc. Todo ese "bootstrapping" de un proyecto también implica tareas repetitivas y consumidoras de tiempo. ¡Automatizémoslas!
En Python la herramienta más conocida de scaffolding+bootstrapping es cookiecutter. Aunque es una herramienta hecha en Python (los templates se definen con Jinja), no se limita a crear boilerplate para proyectos Python ¡Está lleno de templates cookiecutter para cualquier tipo de proyecto!
cookiecutter es genial, pero sólo se ocupa del bootstrapping inicial de un proyecto. ¿Qué pasa cuando las convenciones cambian o adoptamos una nueva preferencia? Por ejemplo yo hace mucho usaba Nose como framework y runner de testing, y ahora uso Pytest. Python mismo reemplazó el viejo formato setup.py por pyproject.toml. Y así un montón de cosas.
De nuevo, si tenemos muchos proyectos, cambiar lo mismo en muchos lados es un trabajo aburrido y repetitivo.
Por ese motivo mi plantilla se basa en copier que es en muchos aspectos igual a cookiecutter (acá hay una tabla comparativa) pero soporta actualizaciones de los proyectos generados, es decir que cualquier proyecto que se inició con la plantilla puede aplicar las novedades con un simple comando.
Mi cuerpo plantilla, mi decisión
El template asume Python 3.12+ con layout src/ y configuración unificada en el pyproject.toml. El backend para build
es uv_build que es más que suficiente para proyectos "python puro" (sin extensiones compiladas). Se declara un script (opcional) como entrypoint que usa argparse e incluye --version y --help. Si bien muchas veces prefiero typer como framework para CLIs (especialmente por su autocomplete), mejor dejarlo simple por defecto.
Obviamente uso uv para gestionar las dependencias y el entorno. Si bien el proyecto inicial no declara dependencias productivas (porque no se define ninguna "lógica de dominio" 1 ) sí declaro varios dependency-groups, un mecanismo definido en la PEP 735 que organiza dependencias en conjuntos separados según su propósito --por ejemplo, test, docs, etc-- evitando mezclar todo en las dependencias principales y facilitando instalaciones parciales según el entorno o la tarea. Esto permite, por ejemplo, que cuando instalamos dependencias para compilar la documentación no tengamos que instalar las dependencias de tests (ahorrando precioso tiempo de CI cuando se ejecutan), o cuando verificamos QA con ruff no hagan falta herramientas exclusivas para desarrollo como ipdb. Cuando uv instala o sincroniza las dependencias (por ejemplo, mediante uv sync) busca por defecto el grupo "dev", que en mi template es un metagrupo que incluye dependencias de test, qa y otras cosas.
ruff, ya que lo mencioné, es el linter canónico en la actualidad. De los mismos creadores de uv (y también hecho en Rust) es realmente un misterio cómo logran semejante performance. Cubre lint (reemplazando a flake8, isort y decenas de plugins) y formateo (reemplazando al adelantado black) con un límite de 120 caracteres por línea (porque los 79 recomendados en PEP 8 me resultan escasos para las resoluciones actuales) con un conjunto amplio de reglas activadas, la mayoría de las cuales tienen autofix (y cuando no, los agentes se encargan) así mantiene un estilo pythónico consistente que minimiza bugs. Quizás a futuro active aún más reglas: si es gratis, automático y rápido, las quiero todas.
El paquete incluye tipado "inline" e incluye el archivo py.typed (PEP 561). Los chequeos de tipos se ejecutan con ty, otra de las herramientas de Astral que aún está en alpha, pero ya es usable para los fines de un proyecto nuevo.
El stack de pruebas unitarias usa el estándar de facto, pytest, y coverage.py vía pytest-cov (configurado con un threshold del 100%) con plugins para mocks genéricos y de fechas. Si bien perfectamente se podría usar mock incluido en la stdlib de Python, me gusta el fixture mocker porque no fuerza a usar context managers en el patching. Como dice el Zen, "Flat is better than nested".
Para un proyecto inicial que aún no define su finalidad puede pensarse que no hay mucho para documentar (y quizás basta con el README), pero tener el andamiaje preparado facilita que cuando haya algo sea trivial hacerlo. Por eso la plantilla incluye una carpeta docs/ con la estructura inicial. Acá podría haber usado mkdocs que es una opción cada vez más popular, pero me mantuve en el clásico Sphinx usando myst-parser para escribir en Markdown (solía gustarme reStructuredText pero sé reconocer al campeón). Incluyo un par de extensiones mías ya configuradas: sphinx-mermaid para diagramas y richterm para incluir "capturas".
Luego de crear el código, ejecutamos algunas tareas. Por ejemplo se hace el primer sync (que instala dependencias de desarrollo), y se crea un primer commit con git. Luego, si GitHub CLI está instalado, se crea el repo en GitHub, se pushea y se lanza el primer workflow sin pasos manuales.
Los tests creados así como los chequeos para que no se está infringiendo QA (ruff/ty) se verifican en un workflow de CI que se ejecuta en cada push o PR y corre los tests en todas las versiones de Python en una matriz. Las herramientas que lo soportan están configuradas para generar salidas de errores o warnings en formato de anotaciones de GitHub de modo de poder navegarlos en el contexto del código.
Otro workflow es el encargado de realizar los releases. El flujo típico de un release es make bump + make release (incrementar la versión y commitear e iniciar un release de GitHub). El Workflow detecta este evento, arma los wheels (vía uv build) que adjunta al release en GitHub y además usa el mecanismo de Trusted Publishing para subir la nueva versión directamente a PyPI. Además, se compila y se actualiza la documentación que se sirve desde GitHub Pages (si el repo es público).
El mecanismo tradicional para subir paquetes a PyPI implicaba usar herramientas como twine que requieren un token o un usuario y contraseña. El protocolo Trusted Publishing en cambio gestiona dinámicamente esta autenticación (usando el protocolo oidc), por lo que no hay que gestionar (ni rotar) estos secretos.
Como lamentablemente este paso aún no se puede automatizar porque la API de PyPI no expone endpoints para este registro, lo único que hay que hacer de manera manual, por única vez, es registrar el paquete y el workflow asociado. En mi caso el workflow es cd.yml y el environment lo dejo en blanco.
Cuando se ejecuta copier con una plantilla se lanza un cuestionario: nombre del paquete, autor, usuario de GitHub, esas cosas. Todo lo que pude automatizar aquí para ofrecer defaults con sentido lo hice, para que respondas lo mínimo imprescindible. Por ejemplo el nombre del proyecto se infiere del directorio que se pasa como argumento, el nombre e email del autor se obtienen de git y el usuario de GitHub desde la API vía GitHub CLI.
Un detalle fruto de la experiencia: muchas veces me sucedió que ideo un nombre para un proyecto y a la hora de publicarlo me percaté de que el nombre ya está ocupado (mi reciente textual-tetris se llamaba "textris" originalmente, pero alguien me ganó de mano). Por eso el wizard se encarga de validar que el nombre que le queremos dar al paquete está disponible haciendo una simple consulta web a PyPI, y en caso de que esté ocupado nos propone un sufijo.
En el proyecto generado definí un Makefile con una serie de atajos para "el día a día". Por ejemplo, si querés compilar la documentación localmente en epub, no tenés que acordarte los argumentos para Sphinx sino make docs-epub (y viene con un make help para más INRI). Si bien hay herramientas más modernas como just o mise (también existe invoke pero lo aborrezco) el cincuentón make es ubicuo y suficiente para estos humildes fines. Targets como qa, test, docs y release encapsulan los comandos largos y dejan una interfaz uniforme para tareas recurrentes.
Además de código se generan los documentos que típicamente son "copy & paste" como LICENSE y CODE_OF_CONDUCT.md (copiado de Contributor Covenant). No creé por ejemplo un archivo de CHANGELOG porque aprovecho directamente la página de release de Githubs.
Por otro lado, qué tiempos modernos, definí un AGENTS.md con instrucciones básicas para que los agentes de código se ubiquen en el contexto donde meteran sus múltiples manos robóticas.
Actualizaciones con Copier
Quizás la feature más interesante de Copier es que puede actualizar los proyectos ya creados, porque todo programador/a que se precie tiene sus principios, pero con el tiempo los cambia por otros.
Recomiendo la entrevista a Jairo Llopis (uno de los mantenedores de Copier) en este podcast donde define a Copier como una "project life cycle management tool" (en contraposición con un gestor de scaffolding tradicional).
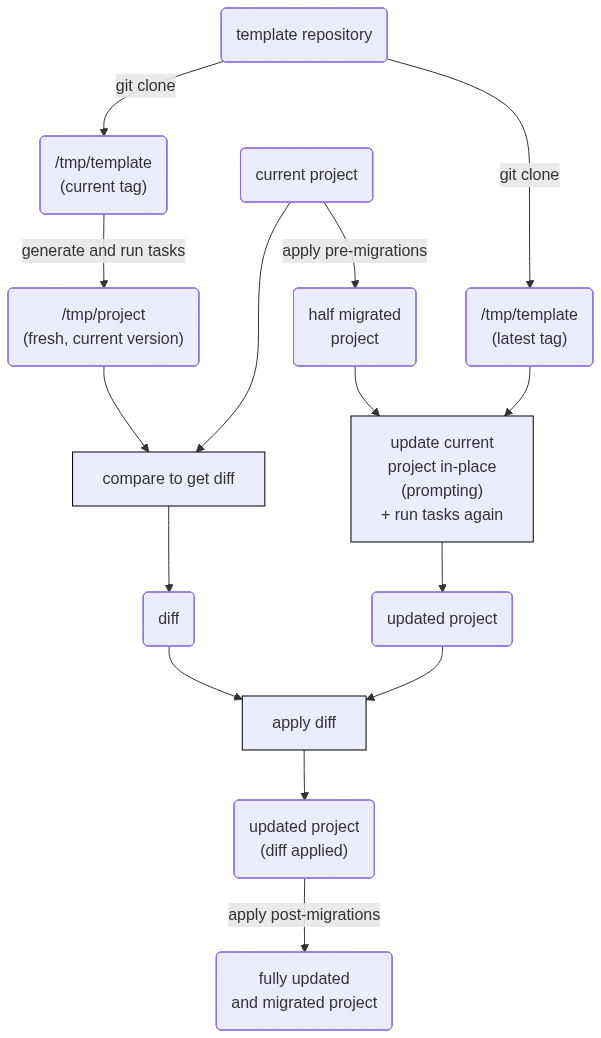
Cuando todo está listo en el proyecto generado, copier deja un archivito .copier-answers.yml con metadatos con la información básica del template que se usó y las variables (las respuestas del cuestionario inicial) usadas. Si hay novedades en el template (por defecto busca tags), ejecutar uvx copier update basta para que se apliquen (o al menos se intente) al proyecto, aún cuando este haya mutado.
El mecanismo que usa para esto no es trivial, implica un proceso de extracción y aplicación de diff (hay que recordar que el template y el proyecto son repositorios totalmente distintos que no comparten historia). Se resume en este diagrama que obtuve de la documentación
No hay bala de plata
Tengo muchos años de Python encima, los últimos especificamente en el área de "developer experience", y vi cómo fueron cambiando las convenciones y evolucionando las herramientas. En particular el packaging en Python siempre fue un trastorno por el cual muchas otras comunidades técnicas se burlaron de nosotros socarronamente. Por suerte en la actualidad se lograron estandarizaciones robustas y la aparición de uv parece haber terminado el debate.
Más allá de que espero que no deba cambiar eso en particular, como se ha visto, hay un montón de otras decisiones tomadas que de acá a un tiempo quizás deba revisar.
Si te interesa usar esta plantilla como base porque te gustan muchas de estas decisiones pero otras no te cierran y no te basta con resolverlas directamente en el proyecto generado (supongamos que no te interesa el Makefile porque usas Windows y te da fiaca: borrás el archivo y listo) entonces el camino es hacer un fork y hacer tus propios cambios. Estrictamente es lo que hice yo: todo comenzó como un fork de este template.
Espero que te sirva y ¡que viva el software libre!
-
Así como en los últimos años hemos ido revisando y politizando el lenguaje en nuestra industria evitando (o tratando de evitar) el lenguaje sexista, esclavista o belicista, también deberíamos dejar de pensar siempre en términos estrictamente capitalistas al software. Te estoy mirando a vos, "lógica de negocio". ↩
Comentarios
Comments powered by Disqus